
中英文文本文件的压缩传输与恢复
实验要求
问题概述

总结
- 压缩中英文文本文件可以减少存储空间和传输时间
- 压缩文件便于组织和管理,还能通过校验和机制保护数据完整性,并支持密码保护以确保安全性。
- 本课程设计采用哈夫曼编码/解码方案,旨在检验编程和数据结构运用能力,并为后续学习信息安全、网络安全和密码技术奠定基础。
实验要求
- 基础功能

- 扩展功能
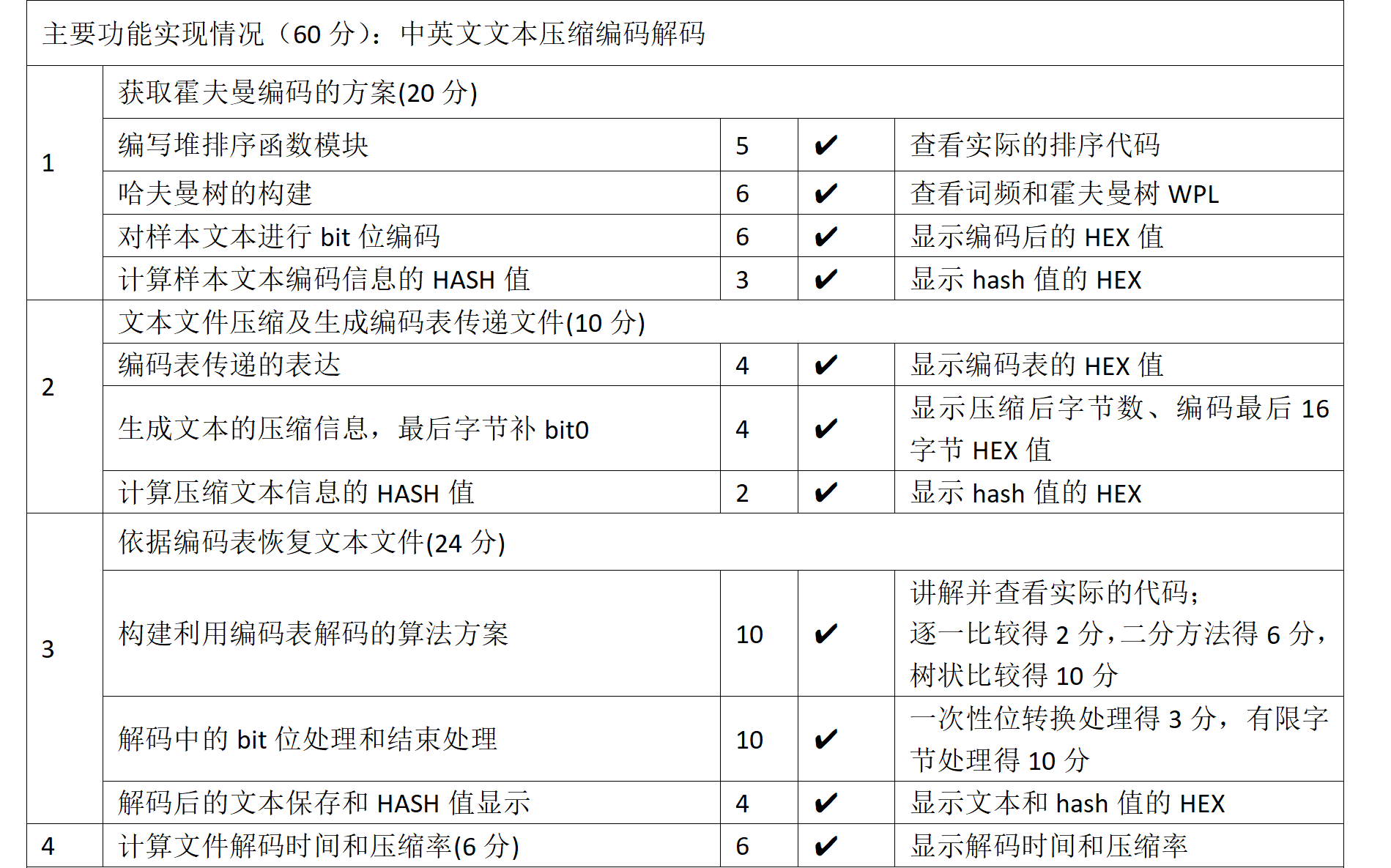
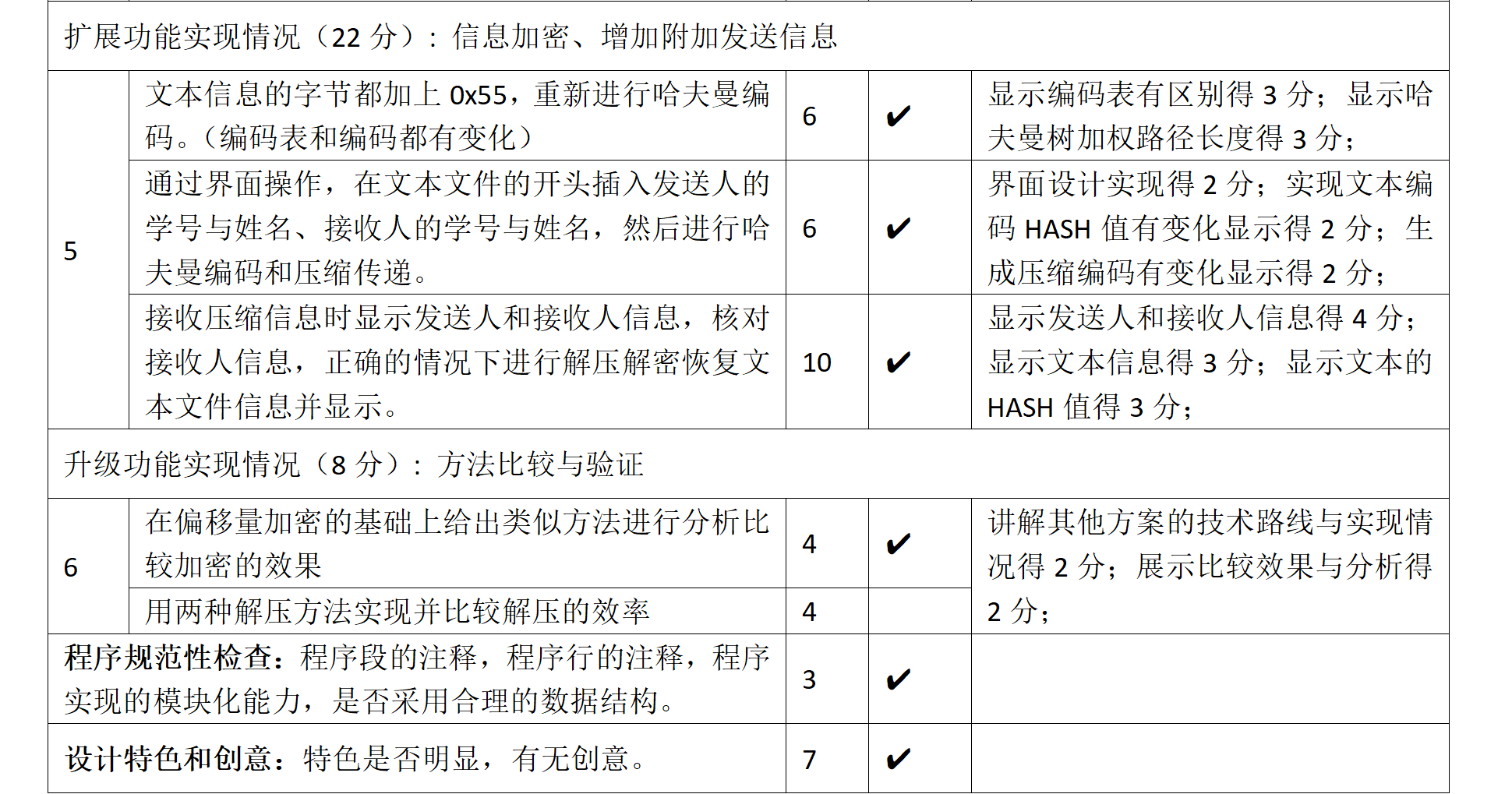
功能模块
程序由四个功能模块构成,交互界面、压缩处理、解压缩处理、公共处理函数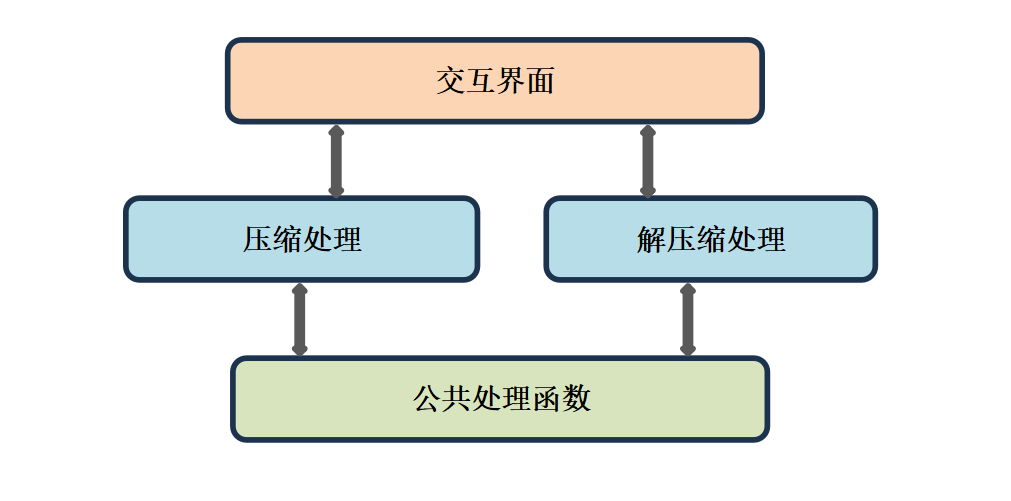
以上为题目大致要求,帮助你快速获取题目信息,接下来谈一谈我的理解,希望对你解题有所帮助。
实验过程
我认为该实验可以分为
文件读写
建哈夫曼树,得哈夫曼编码
压缩和解压缩
下面我将从这三步带着了你一步一步摘取胜利的果实
1. 文件读取
我认为这是
有同学问中英文压缩时如何判断读取的是中文还是英文,因为一个英文字母可以用一个字节表示而一个中文字符可以用多个字节表示,以及读取到空格怎么办,读到标点符号怎么办。
到这里是我们的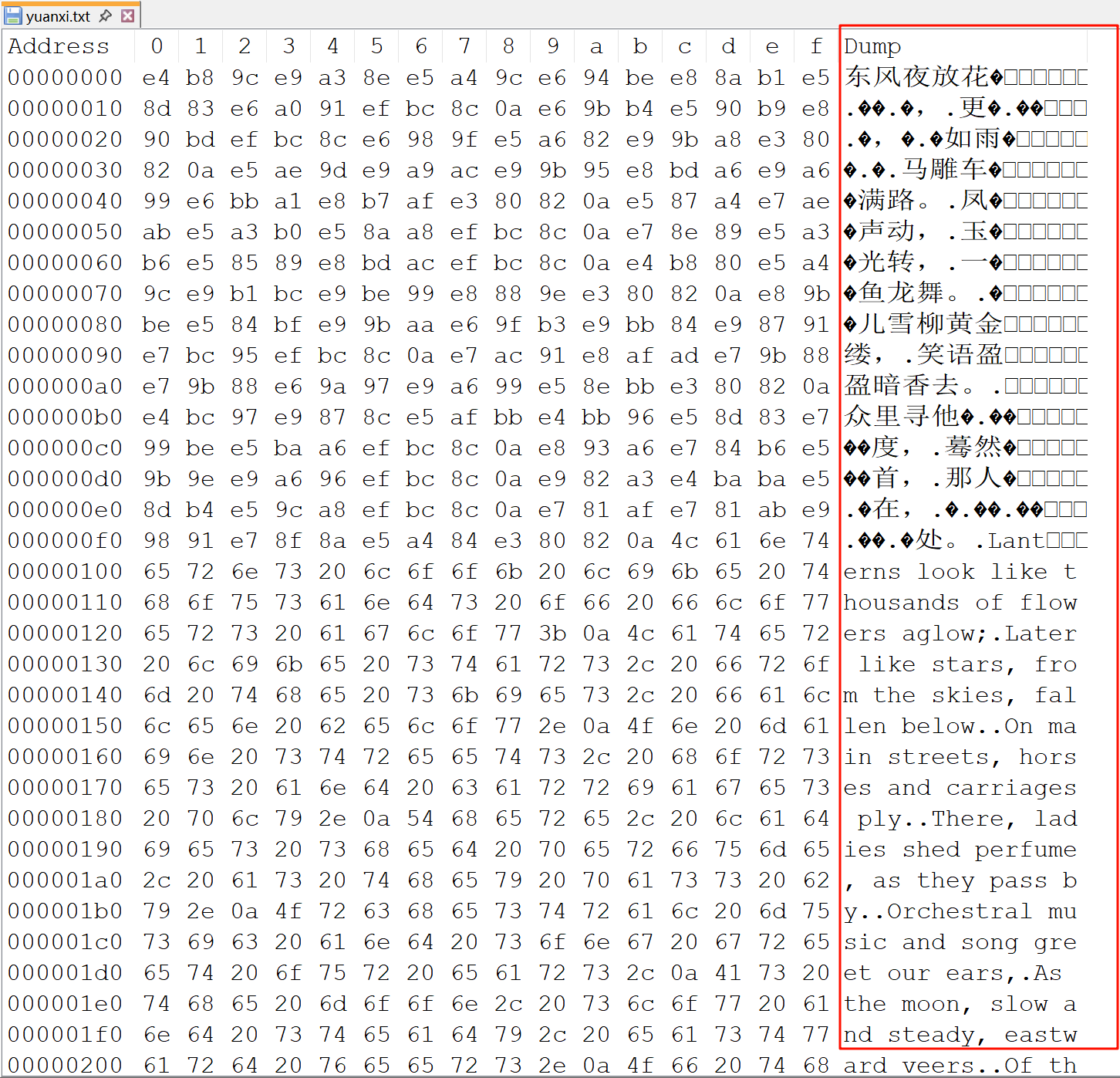
可以看到,无论是中文还是英文,文件都是以字节进行编码的,所以我们对文件的认识从字符的角度转换成字节的角度,这是第一个Leap。
文件读取的0x00 ~ 0xff,最多有256种类型。由此我们可以以字节为单位,以字节对应的字符(ASCII码)为对象,统计文件中每一种字符出现的次数(频率)。[嘿嘿,到这里你是否很熟悉呀,这不就是哈夫曼编码吗] 所以我们建立哈夫曼树的标准就是字符(这里的字符不是文本中的字符,而是字节对应的ASCII码,要注意区别哦)的频率,这是第二个重点。
2.建哈夫曼树,得哈夫曼编码
建立哈夫曼树的依据就是字节对应的ACSII的频率,这个很容易。我认为建立哈夫曼树的时候有
遍历哈夫曼树得到哈夫曼编码不难,这里只有一个重点,就是为了得到尽可能高的压缩效果,约定采用bit的位来表示每位编码值,而不是0/1来表示。因此你需要考虑当哈夫曼编码长度不是8的倍数时需要先补0再转换。示例如下
3.压缩和解压缩
压缩时根据code.txt文件和原文本文件进行压缩,这里有一个很容易犯错的点。
起初我以为是根据code.txt文件中已经对应的字符和bit位编码,去替换源文件中的字节,解压时再遍历code.txt文件进行解码,然而这样会增大压缩文件的占用内存,因为bit位编码存在尾部补零的可能,多出来的零没有实际意义(不属于哈夫曼编码)。
所以这里的重点是压缩时是将源文件按照哈夫曼编码压缩,而不是bit位编码压缩,这里压缩后的文件后缀为.hfm,即压缩文件,大家可以尝试用Notepad++或者VScode的Hex插件打开文件看看里面的内容。
解压缩时有
到这里你就已经基本实现了实验的基础要求啦📢📢📢至于实验的进阶部分,我分享一下我的做法🌟🌟🌟
进阶实验
信息验证
理清信息验证的逻辑,是
你似乎听起来很容易,但实际上有很多细节需要处理
第一是发送方加在首部的信息是需要写入文件中并和文件一起压缩发送出去的,但是我们不能破坏原文件内容,因此可以生成一个临时文件暂存原文件内容或者保持源文件不变,将临时文件作为发送对象。
第二是接收方接收时文件处于压缩状态,如何进行头部信息验证呢,你可能会想先解压再验证呗[嘿嘿,你个小机灵鬼] 但是这样文件不就已经被解压了吗,而实际上
加密
加密的方法有很多,题目要求使用偏移加密,即发送方在原文件压缩前在每一个字节加上一个偏移量,接收方解压缩后再减去偏移量(请反复阅读并理解这个顺序,因为偏移加密加上头部信息验证之后,验证和加密解密的顺序非常容易使人晕头,我也是在这里卡了好久好久)。
这里有一个小细节,就是在文件的每一个字节加上或减去偏移量时不需要取模,你可以思考一下这是为什么。
这里提醒一下,如果大家既有信息验证,又有加密,请在设计时认真思考一下验证和加密的先后顺序[这里有个大坑]
hash验证
文件提供了FNV-1a 64位哈希算法,算法如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// FNV-1a 64位哈希算法的初始值
#define FNV1A_64_INIT 0xcbf29ce484222325ULL
// FNV-1a 64位哈希算法的质数
#define FNV1A_64_PRIME 0x100000001b3
uint64_t fnv1a_64(const void *data, size_t length)
{
uint64_t hash = FNV1A_64_INIT;
const uint8_t *byte_data = (const uint8_t *)data;
for (size_t i = 0; i < length; i++) {
hash ^= byte_data[i];
hash *= FNV1A_64_PRIME;
}
return hash;
}
这里我们可以简单改写函数参数,入口参数为文件名,出口参数为hash运算后的结果,这样可以使哈希函数使用更便捷。
解码时间和压缩率
这里比较简单,可以最后优化时完成1
2
3
4
5
6#include <time.h>
// 计算解码时间
clock_t start = clock();
// 解码函数
clock_t end = clock();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 获取原文件大小
fseek(fOriginal, 0, SEEK_END);
long originalSize = ftell(fOriginal);
fseek(fOriginal, 0, SEEK_SET);
// 获取压缩文件大小
fseek(fCompressed, 0, SEEK_END);
long compressedSize = ftell(fCompressed);
fseek(fCompressed, 0, SEEK_SET);
// 避免除零错误
if (originalSize == 0) return 0.0;
// 计算压缩率(压缩文件大小 / 原文件大小)
return (double)compressedSize/(double)originalSize;
头文件
下面是我整个程序的头文件,可以参考一下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112#ifndef MAIN_H
#define MAIN_H
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include <time.h>
// --------------------- 宏定义 -------------------------
#define MAX_ID_LENGTH 20
#define MAX_NAME_LENGTH 50
#define OFFSET 0x55 // 偏移量
#define XOR_KEY 0xAA // XOR密钥
#define FNV1A_64_INIT 0xcbf29ce484222325ULL // FNV-1a 64位哈希算法的初始值
#define FNV1A_64_PRIME 0x100000001b3 // FNV-1a 64位哈希算法的质数
// --------------------- 全局变量 ----------------------------
int encrypt; // 0表示未加密,1表示加密
int opt; // 加密方式
int verify_flag; // 用户信息验证 0表示验证成功,1表示失败
char headinfo;
char baseFilename[20];
// --------------------- 结构体定义 -------------------------
// Huffman树节点结构体
typedef struct HuffmanNode {
unsigned char ch;
unsigned long freq;
unsigned char minChar;
struct HuffmanNode *left;
struct HuffmanNode *right;
} HuffmanNode;
// 存储每个字符编码的结构体
typedef struct {
unsigned char ch;
int codeLength;
char code[256];
} HuffmanCode;
// --------------------- 函数声明 -------------------------
// 询问用户请求是否加密
int askForEncryption();
// FNV-1a 64位哈希算法
uint64_t fnv1a_64(const char *filename);
// 读取文件字符频率
int readFileCounts(const char *filename, unsigned long counts[256]);
// 创建Huffman树
HuffmanNode* buildHuffmanTree(unsigned long counts[256]);
// 交换两个 HuffmanNode* 指针
void swapNodes(HuffmanNode **a, HuffmanNode **b) ;
// 堆化函数:保证以 i 为根的子树满足堆性质
void heapify(HuffmanNode **nodes, int n, int i, int (*cmp)(const void *, const void *));
// 堆排序函数,将 nodes 数组排序(升序排列),参数 cmp 为比较函数,通常传入 compareNodes 函数
void heapSortNodes(HuffmanNode **nodes, int n, int (*cmp)(const void *, const void *));
// 生成Huffman编码
int generateHuffmanCodes(HuffmanNode *root, HuffmanCode codes[256]);
// 将编码表写入文件
void writeCodeTable(const char *filename, unsigned long totalFreq, HuffmanCode codes[256], int numCodes);
// 释放节点
void freeHuffmanTree(HuffmanNode *node);
// 压缩文件
void compressFile(const char *inFilename, const char *outFilename, char *mapping[256]);
// 解压文件
void decompressFile(const char *codeFilename, const char *compressedFilename, const char *outputFilename);
// 偏移加密文件
void encryptFile(const char *inFilename, const char *outFilename);
// 偏移解密文件
void decryptFile(const char *inFilename, const char *outFilename);
// 异或加密
void xorEncryptFile(const char *inFilename, const char *outFilename, uint8_t key);
// 异或解密
void xorDecryptFile(const char *inFilename, const char *outFilename, uint8_t key);
// 插入发送人和接收人信息到文件开头
void insertUserInfo(const char *filename, const char *senderID, const char *senderName, const char *receiverID, const char *receiverName);
// 去掉文件开头两行用户信息
void removeHeader(const char *filename);
// 计算文件压缩率
double calculateCompressionRatio(const char *originalFile, const char *compressedFile);
// 显示文件最后16字节
void displayLast16Bytes(const char *filename);
// 计算WPL(加权路径长度)
unsigned long calculateWPL(HuffmanNode *node, int depth);
// 解压并验证发件人信息
double decryptAndVerify(const char *codeFilename, const char *compressedFilename, const char *finalOutputFilename);
#endif // PROJECT_H
实验展示
下面是一个简单的演示,具体实现请参照实验书
下面是一个完整的演示,具体实现请参考实验书
后记
上次tftp和gns3实验指南发布后,有很多小伙伴给我私信,我也收到很多小伙伴的投喂,在这里感谢大家的支持❤️❤️❤️爱你们哦~
最后内容均为个人理解,如有不对还请各位大佬指正。欢迎大家在评论区留言,也欢迎一起讨论!

- wechat
- alipay

