
Python爬取视频
一、前言
起因是想和npy看一部电影,但是腾讯视频下架了这部电影,于是在某视频网站上找到了该电影的资源,可是这是一个非正规网站 yeah,旁边有小广告的那种 ,而且视频流畅度不高,总是卡卡的。于是想把视频资源爬取下来,这样不仅没有了侧边栏的广告,而且视频非常流畅(简直是very nice)
免责声明
本代码仅供技术学习、学术研究或个人合法用途。使用者应遵守所在国家/地区的法律法规及目标网站的公开政策,禁止用于任何侵犯他人隐私、商业侵权或破坏计算机系统等非法行为。
二、预备阶段
这里补充一些基础知识
视频的主要格式有.mp4、.mov等,而视频平台不会以完整视频的形式将资源放在服务器,而是将视频切片化处理,每10s左右为一个划分,存储在.ts文件中,并将所有的.ts文件信息放在.m3u8文件中。
于是,我们可以通过获取.m3u8文件,进而得到所有的切片视频文件(.ts文件)
爬取一个视频本质上就是让程序模拟用户的方式获取存储在服务器的视频资源,你所能看到的所有资源理论上都是可以爬到的,而你所看不到的(需要特殊权限的资源)理论上是不可以爬到的。
三、实验过程
1.获取m3u8文本内容
这是最关键的一步,难点在于如何找到m3u8文件的位置
首先在播放视频页点击右键检查页面(快捷键为F12),然后刷新页面,搜索.m3u8,找到正确的.m3u8文件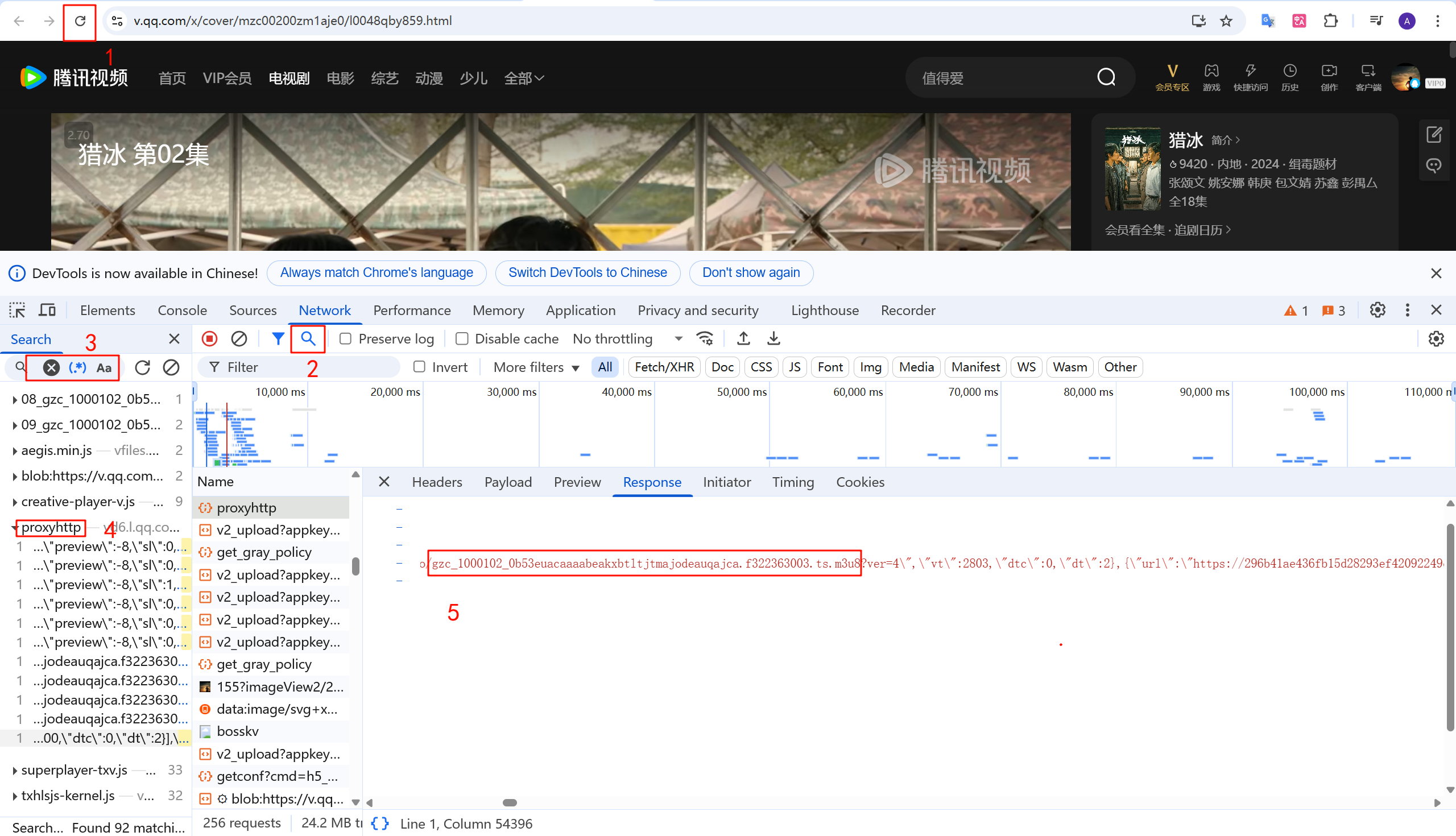
2.从m3u8文件中提取出ts链接
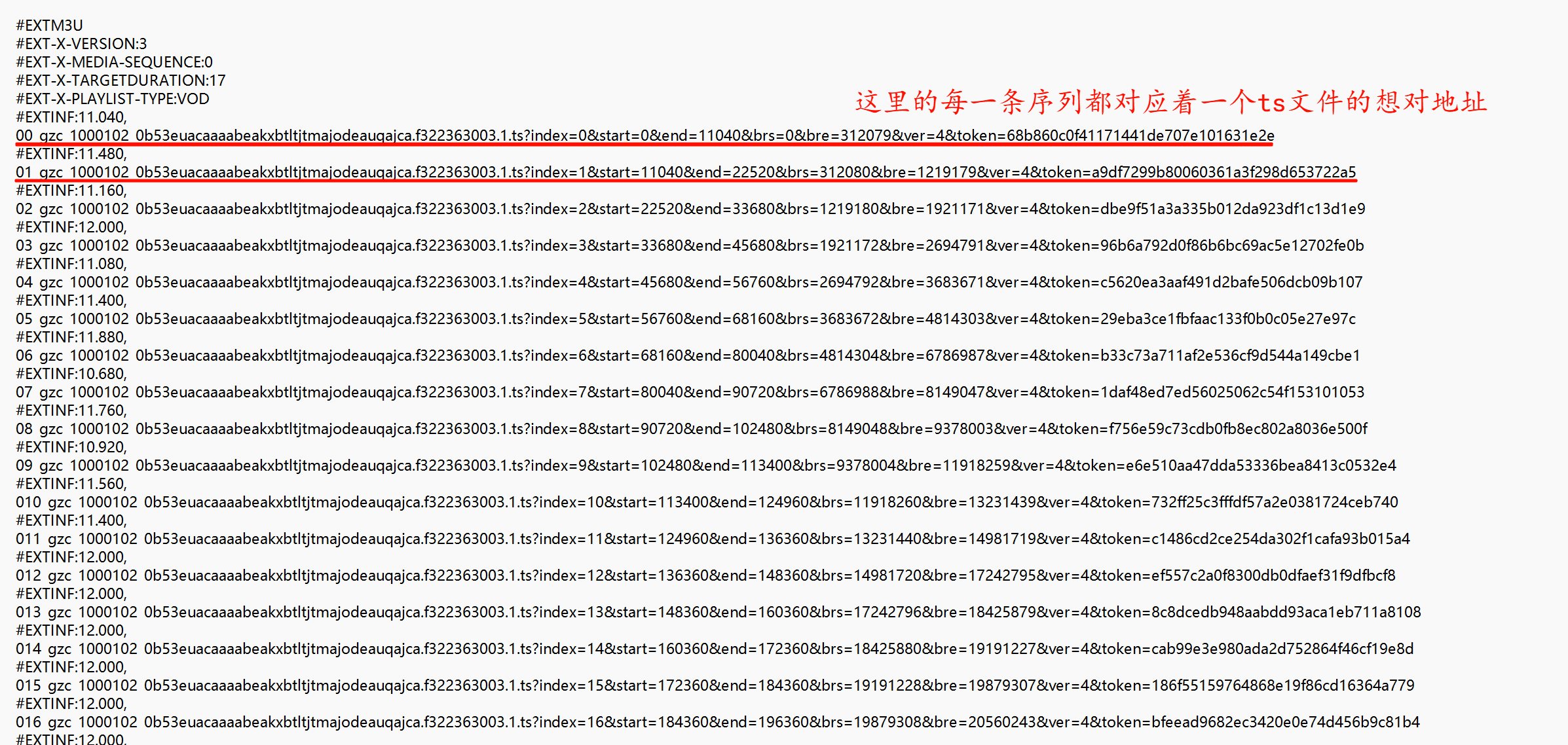

3.获取ts链接对应的内容并将其合并成完整的视频
以二进制流的方式打开文件,并将.ts文件内容顺序写入新建文件中,文件后缀为.mp4,即可实现将片段拼接为完整视频
四、实战演练
1.爬取腾讯视频
Python代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import requests # pip install requests
import re
from tqdm import tqdm # pip install tqdm
# m3u8链接
url = 'https://e5685660564990aa4721a5f7601e6894.v.smtcdns.com/moviets.tc.qq.com/AP4ZQX30o-yQ_HSsPVa81eNid3f6-F1fQyRTsephttEo/B_GRsShIrpiUopFKvbZTGOX9jdoN6DJUGGShkt8zl-NTW_2Z7k_4VvXMdW24r7_ayIKGF-_tEtT4GdGis2Za7jUWvKtDwTFQK0WkIzOWWmMebTfv4McaHYAKtWLWek76v_2YgRffytnPFo45wUcmBwSQ/svp_50112/xwKk9ijThBZN5JS9EqLPnlT83Xhf6Q-sPpVFTdUbt3yQL14i68rfjfYZcPkNNVXLdVjhepH4w7gvi1BCXhF0U6AHbPlFqaNjwHgyyg9KBgEdTNvbtlMLPSZ1CxQNfusoiIMZoSYBKWH-pqGJpqfsHaoJXb6orE2H2vnXcZuAsxYOMtItlBWJ_Z2xZJbKCzwjCl-qOu-dIQjuvI9Yy1mjRXvNcnysQOsBMVXdvrhK_rI/gzc_1000102_0b53euacaaaabeakxbtltjtmajodeauqajca.f322363003.ts.m3u8'
# 从url中切割出ts前缀
sub_ts = url.split('gzc')[0]
# 1.访问 m3u8 地址
response = requests.get(url)
# 2.存储 m3u8 文件内容
m3u8_text = response.text
# print(m3u8_text)
# 3.从 m3u8 文本内容中提取出所有 ts 链接
m3u8_text = re.sub('#E.*','',m3u8_text)
ts_list = m3u8_text.split()
# print(ts_list)
# 4.将ts链接地址拼接成完整视频地址
for ts in tqdm(ts_list):
ts_url = sub_ts + ts
# 5.访问完整的ts链接,获取数据
ts_data = requests.get(ts_url).content
# 6.将ts视频拼接成完整视频
with open('./video/猎冰.mp4', mode='ab') as f:
f.write(ts_data)
2.爬取网页视频
Python代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import requests # pip install requests
import re
from tqdm import tqdm # pip install tqdm
# m3u8链接
url = 'https://vip.ffzy-play6.com/20221019/183_68076fb3/3000k/hls/mixed.m3u8'
# 从url中切割出ts前缀
sub_ts = url.split('mixed')[0]
# print(sub_ts)
# 1.访问 m3u8 地址
response = requests.get(url)
# 2.存储 m3u8 文件内容
m3u8_text = response.text
# print(m3u8_text)
# 3.从 m3u8 文本内容中提取出所有 ts 链接
m3u8_text = re.sub('#E.*','',m3u8_text)
ts_list = m3u8_text.split()
# print(ts_list)
# 4.将ts链接地址拼接成完整视频地址
for ts in tqdm(ts_list):
ts_url = sub_ts + ts
# 5.访问完整的ts链接,获取数据
ts_data = requests.get(ts_url).content
# 6.将ts视频拼接成完整视频
with open('./video/倩女幽魂.mp4', mode='ab') as f:
f.write(ts_data)
 wechat
wechat- alipay

